
this blogger does not exist by Audrey C. '24
join me in the uncanny valley
A reader of the blogs emailed CJ the following, which CJ then forwarded to me:
i remember your posts (college apps, haiku) about robo-CJ, and I wondered if it might make sense to try using a Cycle-GAN to generate blogger avatars, just for the fun of it.
also there are different art styles across the blogger generations so it might be cool to try the newer bloggers with older styles and vice versa etc.
Their idea was pretty up my alley in terms of what I do for my UROP, so I gave it a shot this IAP. For context, CycleGAN is a conditional image-to-image translation model, meaning that you’d input one image within a certain domain (ex. Monet’s painting). Then CycleGAN would spit out the contents of the input image placed in a different domain, such as a realistic photo. Pretty neat huh!

diagram from the CycleGAN paper, linked above
the dataset
To create a dataset to train blogger avatar generation models, I wrote a script using the library BeautifulSoup to scrape a total of 148 avatars illustrated by Shun Liang for student, staff, and alum bloggers. This dataset included both avatars drawn in the current style, old style, and out of style. I should’ve filtered out the ‘out of style’ avatars from the dataset, but I’d never finish this blog if I did everything I should’ve done.01 or more like I threw together most of this blog's content during the wee hours of the morning and only realized later that I could've done certain things better, and redoing things would take a good amount of time

(a) new style, (b) old style (featuring Hamsika C. ’13), (c) out of style (featuring the decisions drone)
this blogger does not exist
State of the art image generation models typically take thousands, if not millions of images to train well, so 148 images was on the tiny end as far as datasets go. Almost all of the datasets that CycleGAN reported evaluation metrics on had >500 images, so I wasn’t confident that CycleGAN could be trained on the tiny blogger dataset. So I decided to first try using the blogger dataset to train StyleGAN-ADA, which was designed to perform well on limited data.02 it's able to do so because of data augmentation: during training, it performs several image transformations (such as rotation, flipping, color adjustments, crops) on each image in the dataset, and interestingly this effectively stabilizes training as if the dataset were magnitudes larger than its actual size Unlike CycleGAN, StyleGAN-ADA is an unconditional model,03 output image is determined without an input label or image so we wouldn’t be able to generate avatars for specific people. Let’s call this unconditional blogger generator BloggerGAN-ADA. There were still some fun things to be done though :).
Here’s a look at the fake bloggers generated by BloggerGAN-ADA:

fake bloggers
BloggerGAN-ADA was biased towards generating avatars with light skin. This was unsurprising as the older style omitted skin tone. The quality wasn’t too shabby though.
A cool and surprisingly simple thing that can be done with StyleGAN is interpolation. How image generation models work is that it maps a latent (basically a random vector) to a matrix representing pixels of an image. These latents form a multidimensional vector space, which during model training, learns meaningful representations of the data’s features. Interpolation takes a weighted average of two latent vectors to see what image that new vector maps to. Higher quality interpolated images indicate that these learned representations are more meaningful.

interpolations taking the weighted averages of the latent codes corresponding to the figures on the right and left most ends.
face to blogger translation and vice versa
While I had relatively few pictures of real avatars, BloggerGAN-ADA could generate an indefinite number04 by giving it randomly generated latent codes to map to an image of unique avatars. This essentially gave us an indefinite dataset to train CycleGAN, which could translate a realistic face into an avatar and also the other way around! CycleGAN’s novel contribution was that the two dataset domains (i.e blogger avatar and real faces) didn’t need to be paired. So I downloaded some weights for StyleGAN-ADA pretrained on FFHQ, a large publicly available dataset of faces, to generate an indefinite number of faces. FFHQ was definitely large enough to be used directly, but since I already had the indefinite dataset generation framework set up, it was convenient to just use that.
Here’s the wall of text above condensed into a diagram:
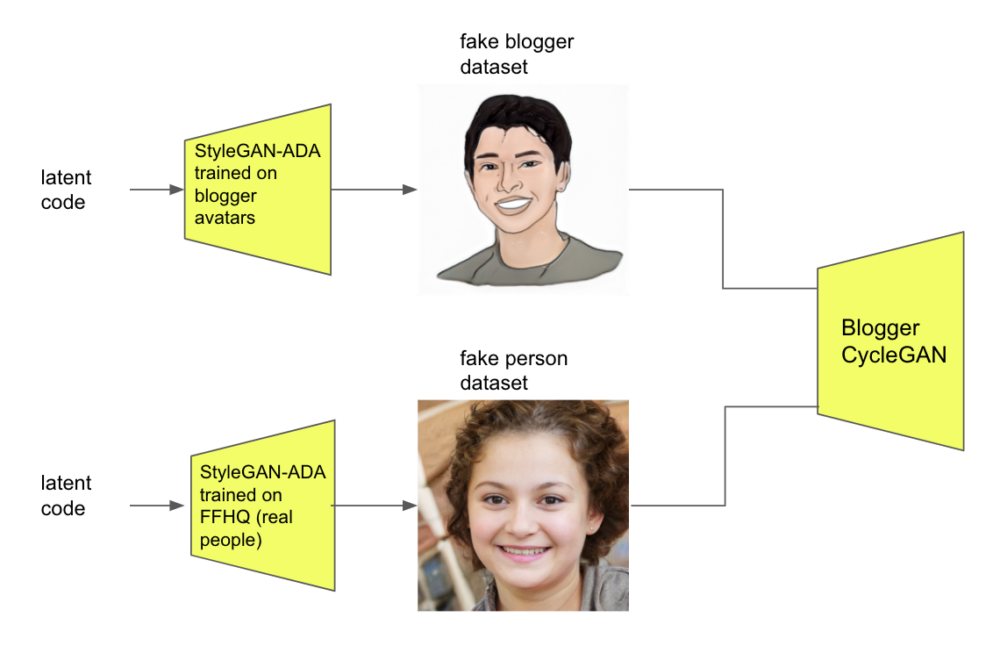
sooo… how well did this work? Real face to avatar translation was a mixed bag. I think mine turned out okay because I was in front of a plain white background, but the model didn’t quite learn how to disentangle foreground from background (i.e CJ’s).

Avatar to real face translation on the other hand…

(a) my avatar. (b) CycleGAN output after training for 5 epochs. CycleGAN output after training for 30 epochs.
I look like a lamprey in (b). (c) seemed to have combined the chin and neck??

(a) Kellen’s avatar. (b) CycleGAN output after training for 5 epochs. CycleGAN output after training for 30 epochs.
Kellen’s sparkly blue eyeliner in (b) is totally a look. Reminds of me of those Monster High dolls. Mint an NFT05 nft's are all the rage in the generative art world, but i think they're ridiculous. out of it, you won’t. (if you do, please give me and Kellen a cut of the $$).

(a) Amber’s avatar. (b) CycleGAN output after training for 5 epochs. CycleGAN output after training for 30 epochs.
That’s a nicely rendered eye in (b), just in the wrong spot. Again the chin invading into the neck situation is happening in (c)
closing remarks
I initially thought that using fake images to train CycleGAN was clever, but in retrospect that probably wasn’t the move. The original FFHQ dataset likely had people in all sorts of framings, but the StyleGAN generated images tended to crop the image above the shoulders. I’m guessing that as a result, CycleGAN never learned how to render shoulders, which it gradually learned to compensate for by elongating faces into necks. Alas classes are starting again and I will soon be consumed by pset hell, so I shall leave this as an exercise to the reader.
“What about style transfers?” you may (or may not) ask. For context, style transfer models apply the style of one image onto the content of another image, like this:

style of Amber’s avatar transferred onto my real face. not bad!
Or this:

Style of my face transferred onto Amber’s avatar. less successful :p
Style transfers are simpler than training a CycleGAN from scratch, but seemed to work better for person to avatar translation! This made sense, as these avatars were a simplification of a person’s face into a few bold lines, solid colors, and relatively simple shading. However, style transfers had a harder time going from simple to complex. Style transfers were also limited by it requiring the manual selection of a style image in addition to an input image during inference,06 making predictions (such as generating images) on a trained model whereas a trained CycleGAN only needed the one input image.
That’s it for now. Hope you enjoyed the cursed pictures!
- or more like I threw together most of this blog's content during the wee hours of the morning and only realized later that I could've done certain things better, and redoing things would take a good amount of time back to text ↑
- it's able to do so because of data augmentation: during training, it performs several image transformations (such as rotation, flipping, color adjustments, crops) on each image in the dataset, and interestingly this effectively stabilizes training as if the dataset were magnitudes larger than its actual size back to text ↑
- output image is determined without an input label or image back to text ↑
- by giving it randomly generated latent codes to map to an image back to text ↑
- nft's are all the rage in the generative art world, but i think they're ridiculous. back to text ↑
- making predictions (such as generating images) on a trained model back to text ↑